How We Think
Published:
- Motivation
- A Unified Perspective on Test-Time Computation: Proposer and Verifier
- Thinking in Contiuous Space
- Thinking with Image
- Thinking with Video
- References
Special thanks to Lilian Weng for her inspiring blog posts, which motivated me to start writing my own.
Motivation
AI model 往往缺乏自主的 “pause and think” 能力, 他们的回答主要依赖于预训练时学习到的固定的回答模式, 这种模式通常被称为 System 1 reasoning。与之相对, System 2 reasoning 更接近人类的思维方式: 一个真正具备推理能力的模型, 应能够根据题目的难度, 动态地分配合适的 computational resource —— 在简单的问题上花费少量的计算资源, 在困难的问题上花费较多的计算资源。
因此,模型在何种情况下需要引入 test-time compute 技术,以及应当采用何种具体方法,正是当前 test-time compute 领域的研究热点。
We are given a prompt and a test-time compute budget within which to solve the problem. Under the abstraction above, there are different ways to utilize test-time computation. Each of these methods may be more or less effective depending on the specific problem given. How can we determine the most effective way to utilize test-time compute for a given prompt? And how well would this do against simply utilizing a much bigger pretrained model?
A Unified Perspective on Test-Time Computation: Proposer and Verifier
Scaling LLM test-time compute Optimally(Snell et al. 2024) 将 test-time compute 技术分为两类:
- Modifying the proposal distribution(输入层面)
这一类方法通过改变 LLM 原有的 proposal distribution(即在给定输入条件下,模型对下一个 token 的概率分布)。主要手段包括两种:- Fine-Tuning:直接对 LLM 的参数进行进一步训练,从而调整其分布。常用方法: Slow-thinking Supervised Fine-Tuning, Reinforcemennt Fine-Tuning
- Self Improvement:让 LLM 在生成过程中不断进行自我检查与修正,通过迭代更新答案来逐步优化输出。
- Optimizing the verifier(输出层面) 这一类方法并不改变 LLM 的 proposal distribution,而是针对同一个问题生成的 (M) 个并行回答,利用 verifier 来聚合或选择最优答案。
- Reward Modeling: PRM(process reward model) 的作用是在 LLM 的长链推理过程中,提供稠密奖励信号,从而帮助模型评估当前回答的质量。相比于 ORM(observation reward model), PRM 提供了更稠密的奖励环境, 并且 PRM 也更加符合人类的推理习惯——最终推理结果的正确依赖于每一步小推理的正确(避免了推理错误但是答案正确的情况)。
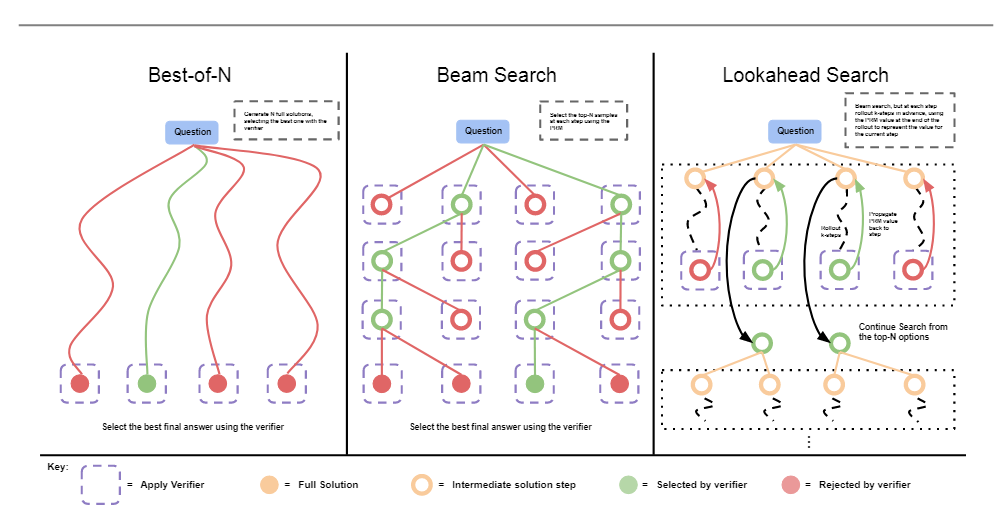
- Search Methods: 非结构化搜索(best-of-N, beam search, lookahead search)以及结构化搜索(MCTS)算法依据 reward model 提供的奖励, 有效平衡了 LLM 推理过程中的探索和利用, 从而引导模型探索并选择更高质量的推理路径。
Thinking in Contiuous Space
Latent Tokens
Latent tokens 指在 LLM 训练或者推理过程中, 动态添加的一批隐式的 tokens。这些 tokens 往往不承载显式语义, 其主要作用有两个方面:
- 扩展 LLM 的表达能力(expressive bandwidth): 由于插入的这批 latent tokens 仅存在于 LLM 的隐藏状态中, 不受具体 token 级别语义的制约, 因此可以显著提升 LLM 的表达能力。
- 增加计算资源: 它们为模型提供了额外的”思考时间”和计算能力,从而有助于生成更复杂、更准确的推理过程。
在 Deliberation in Latent Space(Liu et al. 2024) 中, 作者使用了一个 coprocessor model 来接收 LLM 当前的 kvcache。该 coprocessor 根据传入的 kvcache 生成一批 latent tokens, 并将它们插入到 LLM 的 kvcache 中, 实现 kvcache augmentation 的效果。
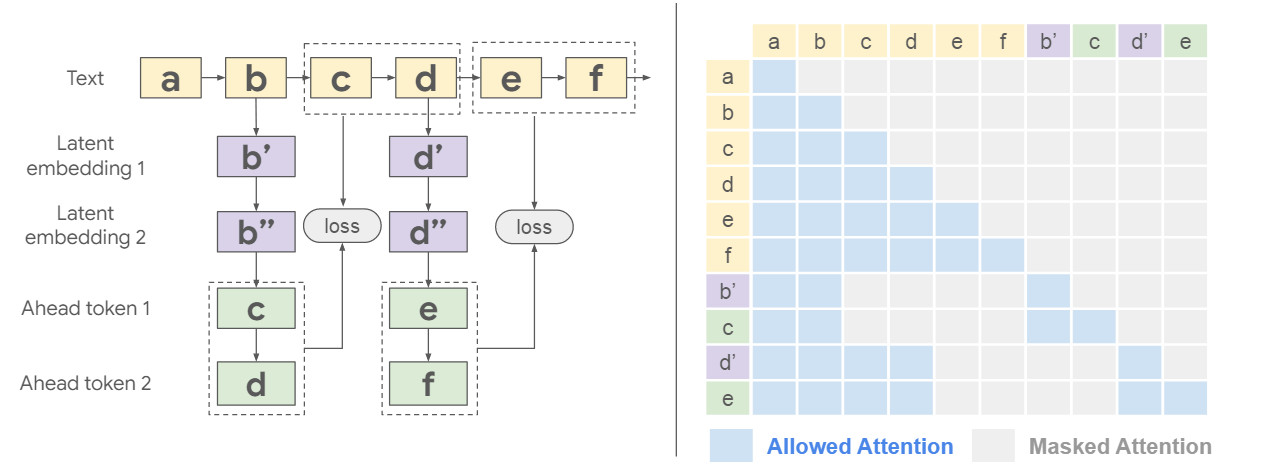 值得注意的是, 这里仅对 coprocessor model 进行微调, 而非直接微调 LLM 本身。这样做的目的是保留 LLM 在预训练阶段获得的能力, 同时避免直接微调 LLM 导致灾难性遗忘。
值得注意的是, 这里仅对 coprocessor model 进行微调, 而非直接微调 LLM 本身。这样做的目的是保留 LLM 在预训练阶段获得的能力, 同时避免直接微调 LLM 导致灾难性遗忘。
在 SoftCoT(Xu et al. 2025) 中, 作者将插入的 latent tokens 视为隐式 CoT (implicit form of CoTs)。在 LLM 正式开始回答之前, 辅助模块会根据输入 prompt 先生成一批 latent tokens, 并将它们拼接到 LLM 的输入 prompt 之后, 然后再由 LLM 对问题进行回答。
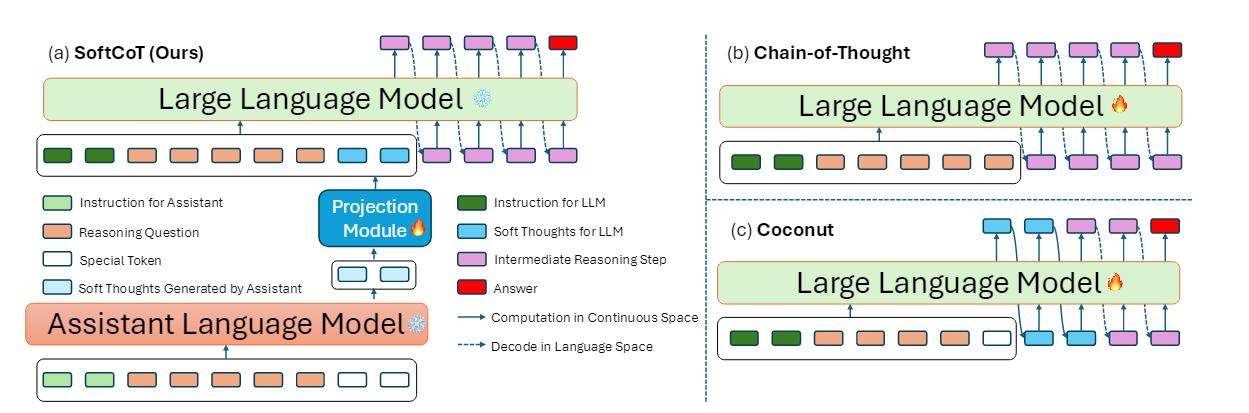
与 Coconut(Hao et al. 2024) 通过自回归方式逐个生成 latent token 不同, SoftCoT 中的 latent tokens 是通过一批 query tokens 获取对应位置的隐藏状态, 然后通过一个 projection layer 将辅助模型的隐藏状态映射到 LLM 的隐藏状态中, 实现对 LLM 的直接增强。
在很多 thinking token 的设置中, 通常不会修改原始 LLM 参数, 而是仅微调 thinking tokens 本身或者辅助模块的参数。实验结果表明, 仅通过微调这些 thinking tokens 或者辅助模块的参数, 就能够达到与直接微调 LLM 参数相当, 甚至更优的效果。这一现象表明, 这暗示了插入的这些 thinking tokens 拥有足够大的 expressive bandwidth, 同时也暗示了 LLM 的表达能力在很大程度上确实受到 token-level supervision 的制约。
Thinking with Image
thinking-with-image 系列工作很大程度上沿用了 thinking-with-text 的核心思路: 即通过让多模态大语言模型(MLLM)在给定图像和问题后, 显式输出文本形式的推理步骤, 从而实现对模型推理能力的有效强化。
Multimodal-CoT(Zhang et al. 2023) 中将多模态问答任务拆解成两个阶段: rationale generation 和 answer inference。在第一阶段, 作者将图片和问题同时输入给第一个 MLLM, 该 MLLM 负责生成针对该问题的推理; 在第二阶段, 第二个 MLLM 接收来自第一个 MLLM 的推理以及原始的图片和问题作为输入, 输出最终答案。
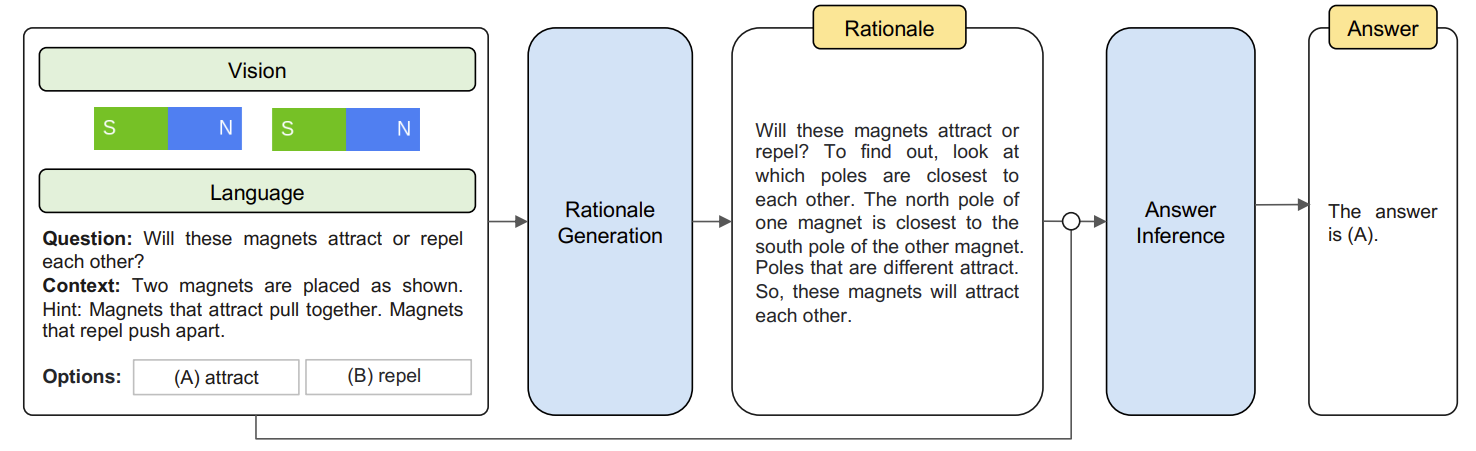
该方法使用 SFT 训练模型。由于 ScienceQA 和 A-OKVQA 提供了人工标注的思维链, 便于进行 SFT, 因此作者选用了这两个数据集进行训练和测试。
与 SFT 训练模型相对, 自从 DeepSeek-R1(Guo et al. 2025) 证明强化学习能够显著提升模型的推理能力之后, 也有很多工作尝试在多模态领域利用 GRPO 等强化学习后训练方法, 从而赋予 MLLM 多模态的推理能力。
Visual-RFT(Liu et al. 2025), VLM-R1(Shen et al. 2025), R1-V(Chen et al. 2025) 等一系列工作将 GRPO 方法从文本模态迁移到多模态任务中, 并取得了显著的效果, 进一步证明强化学习算法同样可以增强 MLLM 的推理能力。 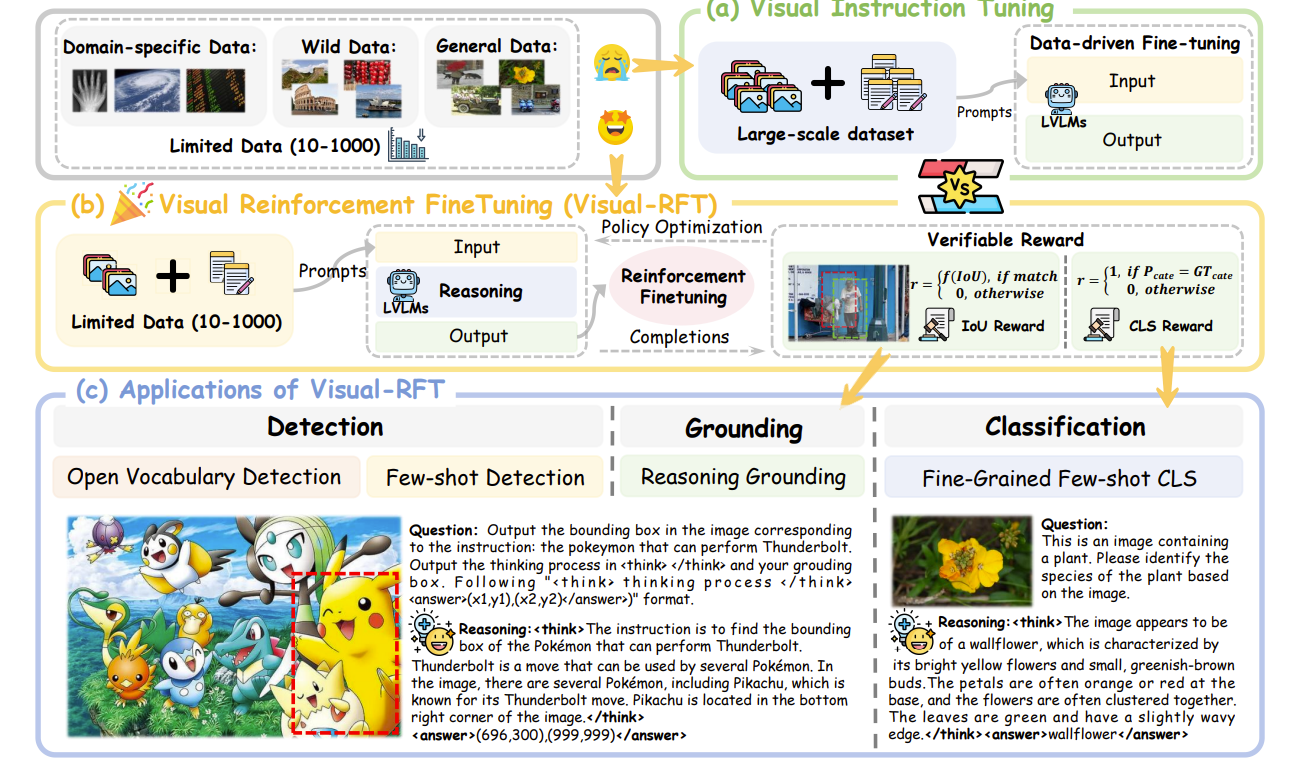
需要意识到,多模态的推理方式与纯文本推理有所不同:人类在解决视觉问题时往往是边看边思考的。如果仅仅利用一次图片信息进行推理, 就无法充分模拟这种”动态观察—推理”的过程, 容易遗漏关键信息, 导致推理不够全面。在 More Thinking, Less Seeing(Liu et al. 2025) 发现: 如果仅将图像作为视觉输入送入多模态大模型的感知层, 模型对视觉信息的关注度会非常低。尤其在 VQA 形式的 Chain-of-Thought 推理中, 模型往往更倾向于依赖其生成的文本信息, 从而进一步忽视图像内容, 导致视觉信息严重丢失, 很容易引发视觉幻觉(hallucination)。值得注意的是, 这种现象在经过强化学习以增强推理能力的模型中表现得更为严重。
因此, 为了降低多模态大模型的幻觉并提升其推理能力, 将图片这一视觉信息动态地融入 MLLM 的推理过程(而非单纯进行文本推理)是一种十分自然的思路。而一旦涉及到在推理过程中动态利用图片, 通常就需要 agent 调用相应的图像处理工具。
Visual Sketchpad(Hu et al. 2024) 中针对不同任务场景(例如数学几何题、复杂视觉推理)允许模型通过 python 代码的方式调用特定的工具进行处理(例如数学函数题使用 matplotlib 绘制函数图像) 边思考边使用工具处理图片。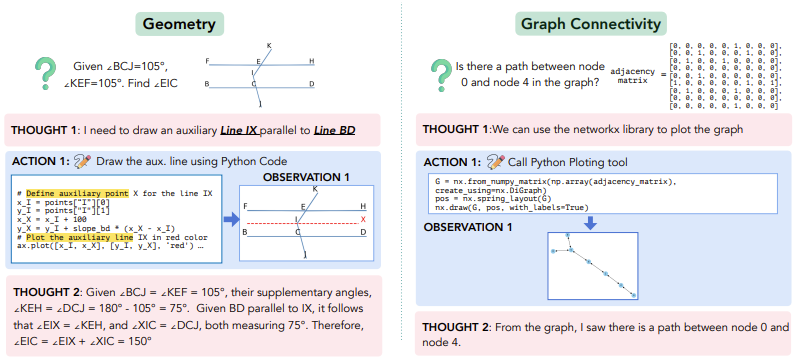
基于 ICL (in-context learning) 的工具调用方式缺少了模型对工具使用的自身探索, 并且缺乏灵活性。因此, VisualToolAgent(Huang et al. 2025) 中使用了强化学习 GRPO 策略训练了一个 visual tool agent 专门用于根据当前的任务选择适当的工具。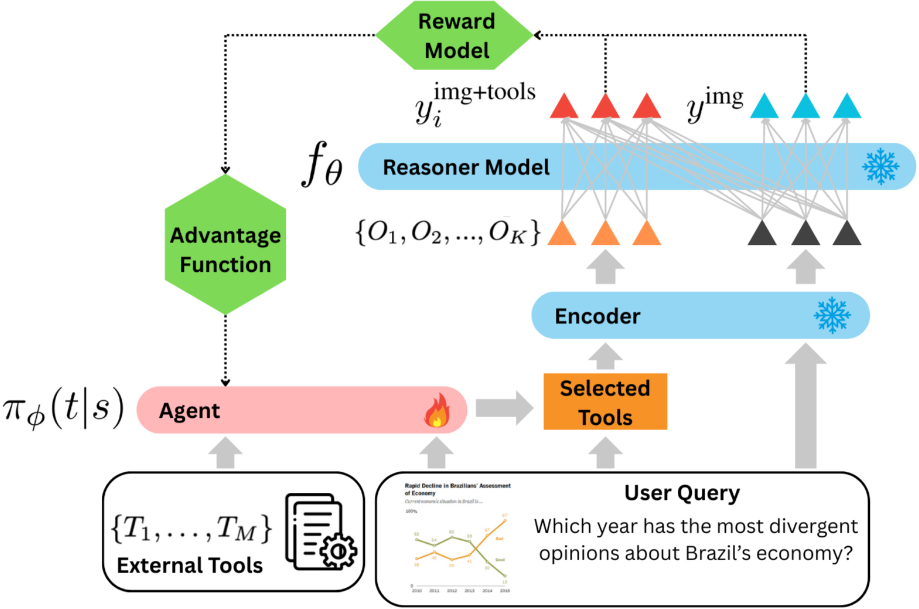 另外, 实验表明这个通过 RL 训练的 agent 可以迁移到其他的多模态大模型上, 说明了对工具的使用也是一种泛化的知识。
另外, 实验表明这个通过 RL 训练的 agent 可以迁移到其他的多模态大模型上, 说明了对工具的使用也是一种泛化的知识。
与基于 workflow 的方式不同, DeepEyes(Zheng et al. 2025) 提出了用端到端的强化学习方式训练多模态大模型的 Grounding 和推理能力。DeepEyes 利用强化学习训练模型自主判断、自主调用工具的能力: 当模型认为当前线索不足时, 会调用图片裁剪工具处理原始图片, 以收集更多细节; 当模型认为已有线索足够时, 模型会输出问题的最终答案。
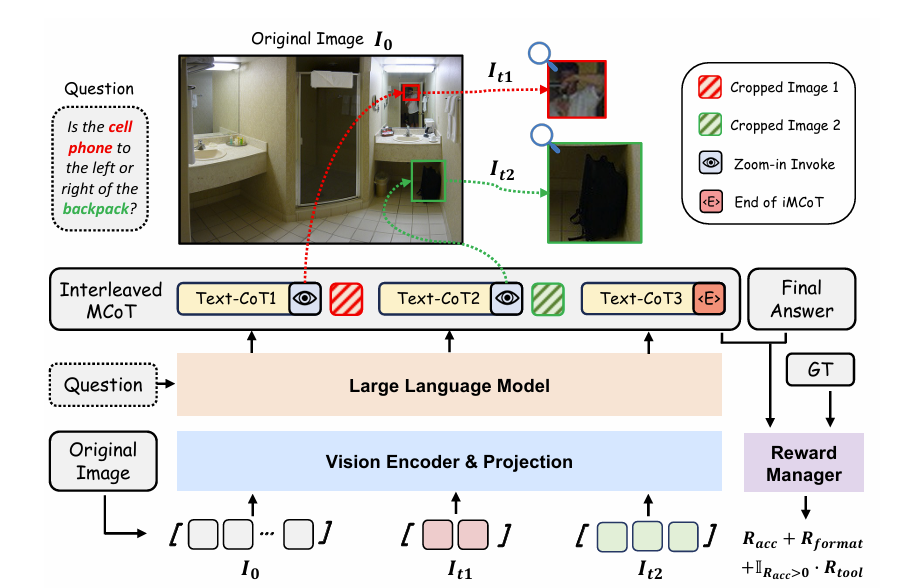
Thinking with Video
视频领域同样也涌现出了大量的 thinking-with-video 相关的工作, 由于视频数据同时具有时间、空间这两个属性, 因此如何高效利用这两个属性, 已成为当前研究的重心。
Long-term Video Understanding
Frame sampling
从时间属性角度出发, 由于视频数据有大量的帧, 而其中存在显著的冗余信息(很多帧与问题无关), 一个自然的思路是筛选视频中与题目有关的关键帧, 而不是简单地进行等间距抽帧。CoS(Hu et al. 2025) 中将关键帧的选择视为 test-time visual prompt optimization, 通过调用 agent 对视频帧进行区分, 将其区分为”有用帧”和”无用帧”。 
在此基础上, Temporal CoT (Arnab et al. 2025) 进一步将关键帧选择与文字标注融合, 旨在进一步增强视频输入特征。在 Temporal CoT 中, 作者使用了两个 VLM, 第一个 VLM 筛选出关键帧并对这些帧进行文字标注; 第二个 VLM 根据筛选出来的关键帧回答问题。这样的做法与人类在回答视频问题时有一定程度上的相似: 我们在看视频时, 会停顿在关键的时间点并进行笔记的记录以防止自己遗忘; 然后在回答问题时会回到之前记录的重要的帧并结合已有的笔记重新理解, 最后做出回答。 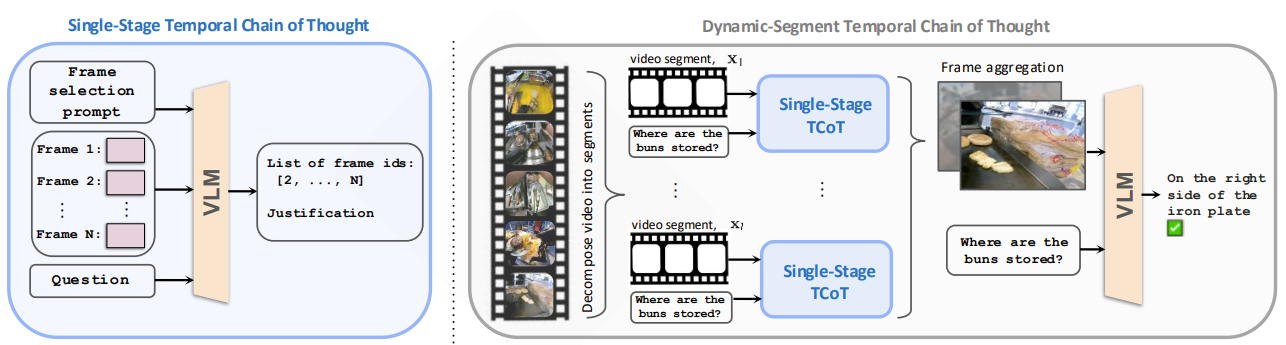
Token compression
Tool-integrated Video Understanding
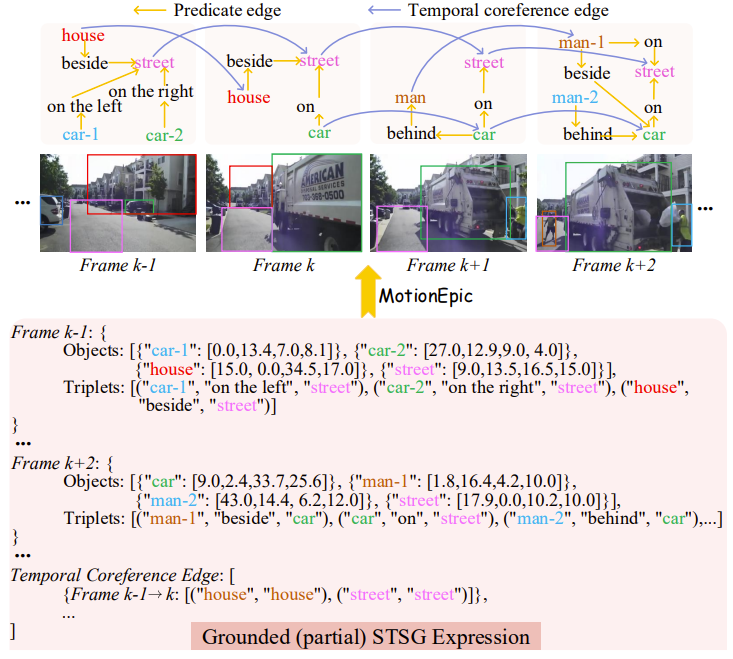
从空间属性的角度来看, 视频数据中每一帧都包含大量的物体及其相互关系。并且与图像数据中静态的物体关系不同, 视频数据中呈现的则是动态演化的物体关系, 这使得建模更具挑战性。Video-of-Thought (Fei et al. 2025) 中提出了一个以 video spatial-temporal scene graph(video STSG) 为核心的多阶段推理框架。该方法采用 tool-using 范式: 首先通过 STSG 捕捉视频中的物体及其动态交互关系, 然后将 STSG 转为文本形式, 以便后续推理模型进一步处理。其核心思想依然属于 test-time visual prompt optimization, 但其创新点在于利用新颖的工具 STSG 结构对视频输入进行增强(预处理), 从而更好地建模视频中的时空关系。